


Trying out Ollama locally

There are many tutorials online about how to setup Ollama and accompanying LLM models locally. Most of them are fairly generic, and it takes me a while to find and aggregate a number of instructions to set up Ollama on my Mac in a suitable format for what I want to do, which is to learn how to interact with Ollama/LLM via Python API. The steps that I have done are as follows.
Setup Ollama
This is straight forward. I downloaded and installed Ollama from ollama.com. After installation, an Ollama GUI popped up. After seeing the recommended command and closing the GUI down (but there is still a tiny Ollama icon on the top-right of the Mac screen), I opened a terminal and tried to just run the ollama command.

I first try ollama serve. With the running llama on top, the command returns an error. It seemed that I already have one ollama instance running.

The standard example command suggested by the Ollama GUI is ollama run llama3.2, but that will give you an interactive chat conversation, which is not what I am looking for. Instead, I try the ollama pull command because intuitively, it feels similar to the act of pulling images for Docker. I pulled two models for testing purpose, ollama pull llama3.1 and ollama pull codellama. I checked for their availability via ollama list

Interacting with LLM via Ollama and Python/Jupyter
I looked for a number of tutorials on how to interact with local LLMs via Ollama and Python/Jupyter. Examples include Running LLMs locally using Ollama and Ollama Jupyter Notebook Intergration. In these examples, interactions with LLMs are carried out separately. I was looking for an example of how to maintain a conversation from inside the notebook. This way, I can design and modify my prompts in a programmatic and repeatable manner. It turns out that I needed to set up a Client object.
First, ollama is installed via pip
pip install ollamaAfter that, the code segment (in one cell) to accomplish what I want is as follows (I use screenshot to retain code highlights).

Line 4: establish a client with the Ollama server running locally (the port mentioned above)
Line 5: select the LLM model
Line 10: messages is a list containing the back and forth questions and responses between the user (user) and the LLM (assitant_reply).
Line 11: contents is a list containing the user’s questions, which we can go back and modify as needed.
Lines 14-32: For each question in contents, the question is sent to the client, and a response (assistant_reply) is recorded, printed to stdout, and also saved to messages as the conversation continues through the loop iteration.
The answer to the first question was somewhat disappointing, but the sonnet was good!
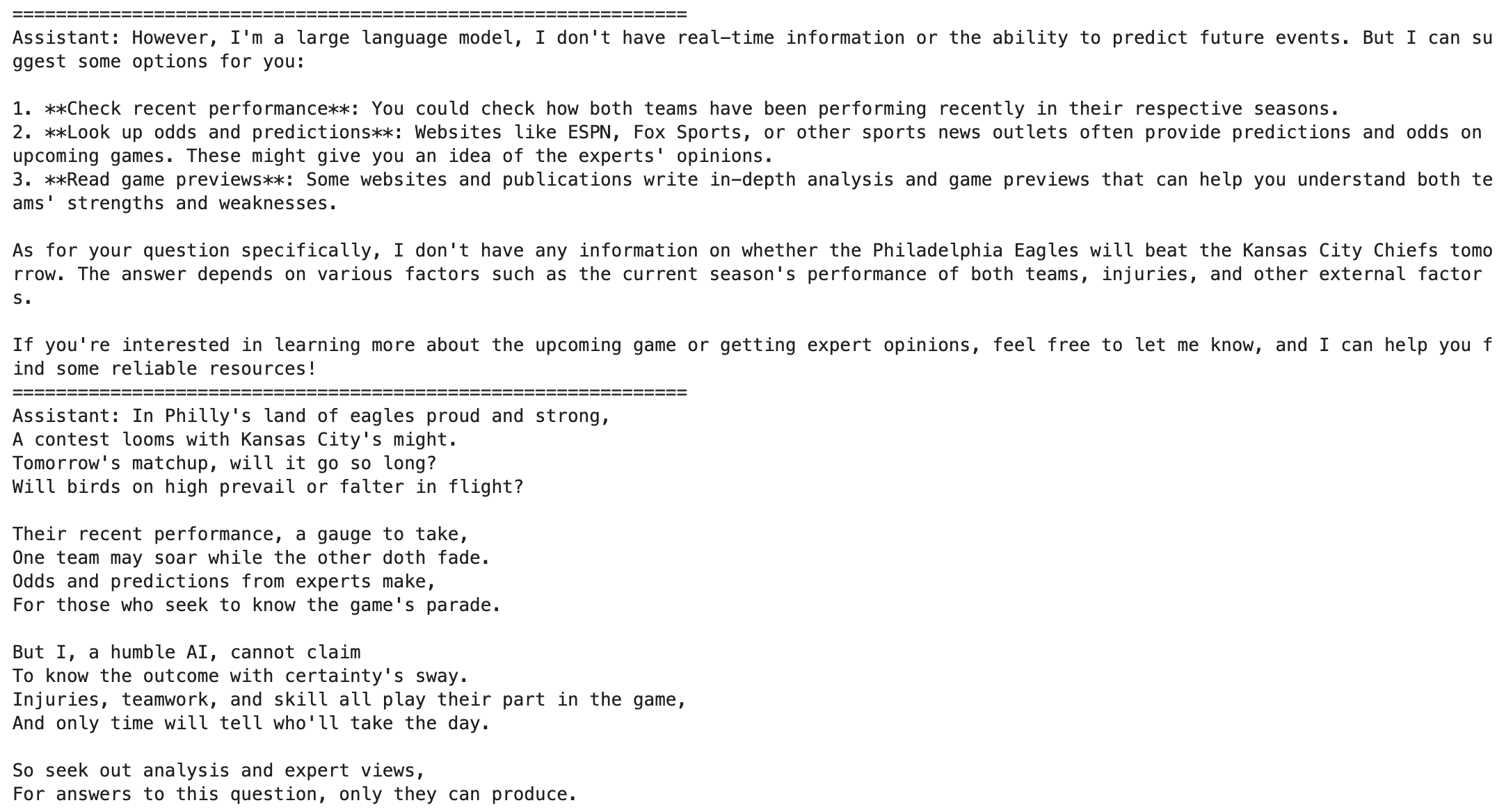
With this, I have a template to play with Ollama in a programmatic manner. This opens up an interesting workflow on whether contents can be dynamically updated based on the responses in messages.